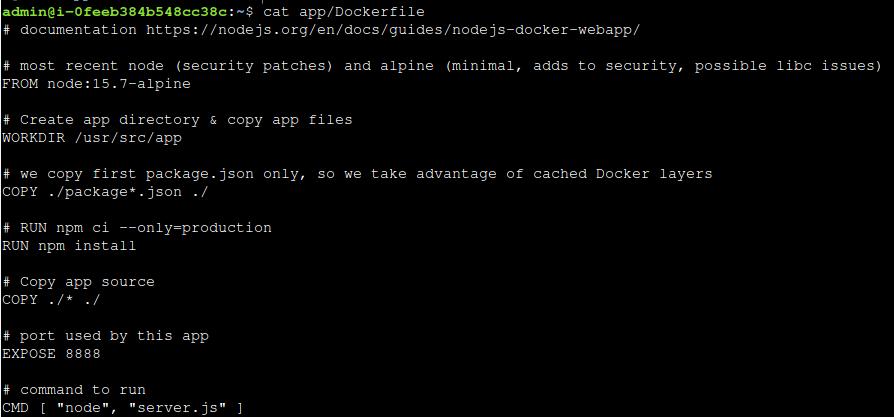
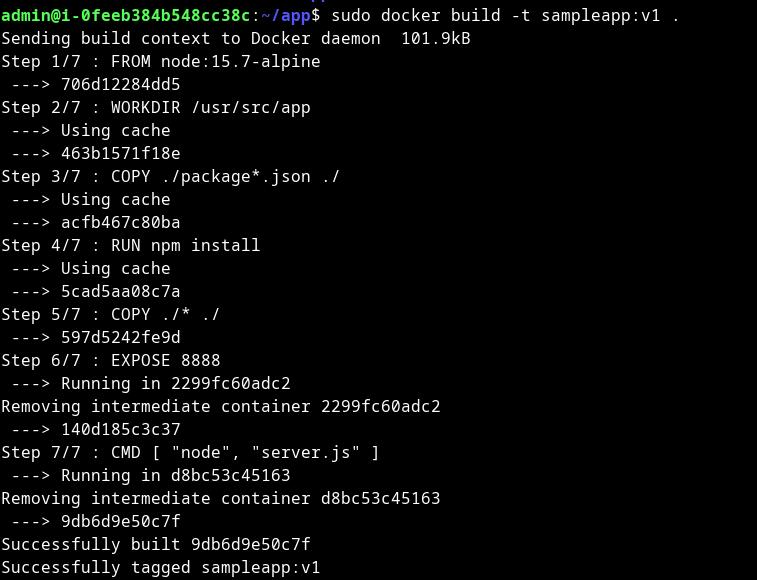
SadServer - Oaxaca solution for https://sadservers.com/scenario/oaxaca
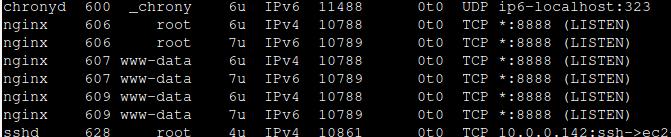
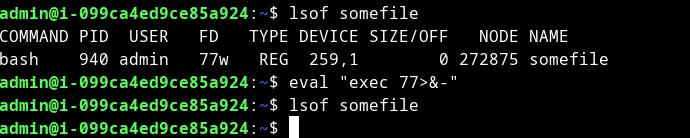
So, the process is started with the current bash - and it has FD (file descriptor) 77. In the picture, you can see "FD/77w". File descriptor usually usage is: 0 for stdin, 1 for stdout, 2 for stderr, and 255 for bash shell - it points to /dev/tty or /dev/pts/N - where is N number. The main process is bash shell and the subprocess is this FD/77 - so by killing the main process we are doomed to destroy our connections. if we run "lsof somefile" - it will show us our bash shell and under /proc/[PID of shell]/fd/77 we have a symbolic link to /home/admin/somefile.
to release the file descriptor we need to re-use the same number with the command: eval "exec 77>&-"
.bashrc contains the running command:
symbolic link to file: