The task was to find out how to run a web server on port 80 and to check if is working properly. URL: https://sadservers.com/scenario/tokyo
After checking logs (apache, systems, etc) and finally running iptables - saw HTTP blocked in iptables.
So running iptables -F solve this issue
(I also added a path for apache /var/www/html/ inside of apache.conf FYI)
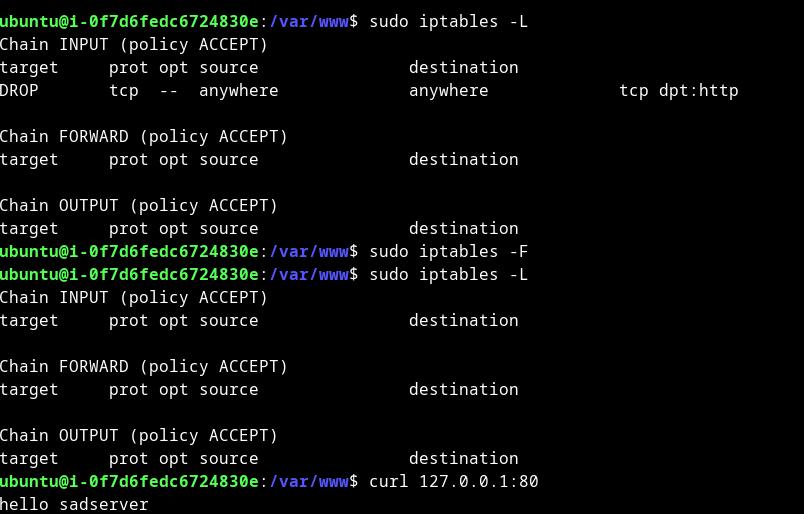

 Solution
Solution
 final commands
final commands